
论文总结
The Role Foundation Models in Neuro-Symbolic Learning and Reasoning
这篇文章提出了一个新的结合神经网络和符号计算的架构NeSyGPT,原理是通过BLIP模型(可以处理图像和文本的配对)提取原始数据中的特征,使用BLIP提取到的信息构建逻辑符号在LAS符号学习器中进行假设的推演。
具体来说,该架构分为两部分,第一部分是使用BLIP提取关于图片相关的信息,第二部分是将提取到的信息进行符号表示并根据提供的背景知识生成逻辑假设。
首先需要对BLIP进行微调以更好地提取信息。微调的方式是人工设计或者大语言模型生成一系列关于图片内容的相关问题以及对应答案,使得BLIP将问题与答案尽量对齐。
得到微调后的BLIP后就可以使用BLIP来提取信息了,并将提取到的信息应用于LAS符号学习器以解决下游任务。
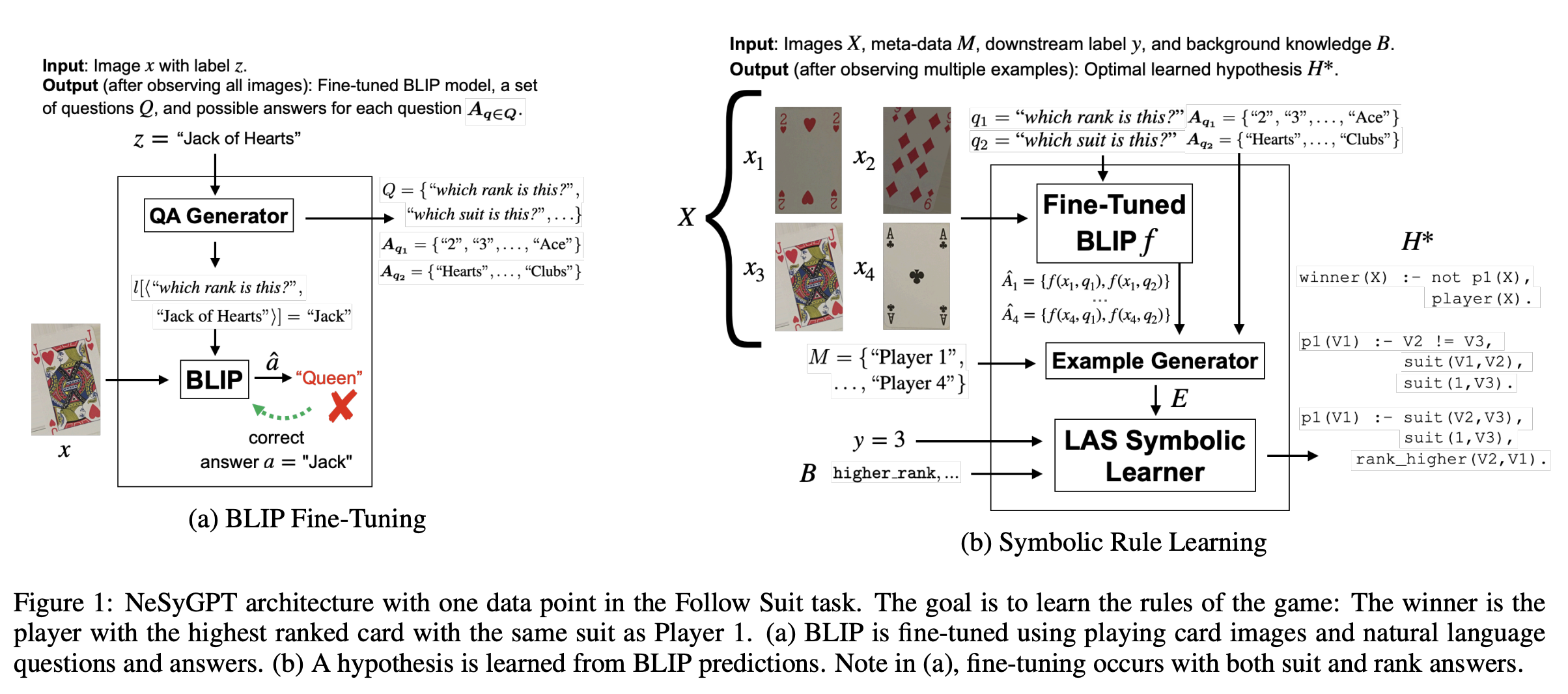
考虑如下任务:输入四张扑克牌的图片和每张扑克牌的所属玩家,以及获胜玩家和使用一阶逻辑表示相关背景知识,生成谁是赢家的一阶逻辑规则。这个任务可以很好地使用上述架构解决。首先,输入4张图片,对于每张图片NeSyGPT首先使用微调好的BLIP询问每张图片的花色和点数信息并给出答案(具体询问什么问题需要根据任务本身来指定,可以人工设计也可以使用大语言模型生成)。得到的答案就可以作为图片的特征,结合牌的所属玩家和标签信息(即谁是赢家),训练一个LAS符号学习器,该符号学习器可以根据背景知识和BLIP得到的信息生成以一阶逻辑表示的假设规则(有些像ILP?)。
Neural networks for abstraction and reasoning: Towards broad generalization in machines
这篇文章提出了一种叫感知抽象与推理语言(PeARL),使用这种语言DreamCoder可以自动生成解决ARC任务的代码。ARC任务有点像IQ测试题,因为样本量比较少而且假设空间复杂难以使用概率模型进行解决,但是人使用推理能力能解决,所以这类问题可以用来测试机器的“推理能力”。DreamCoder是自动生成DSL(Domain-Specific Language)的算法。一个DSL如下:

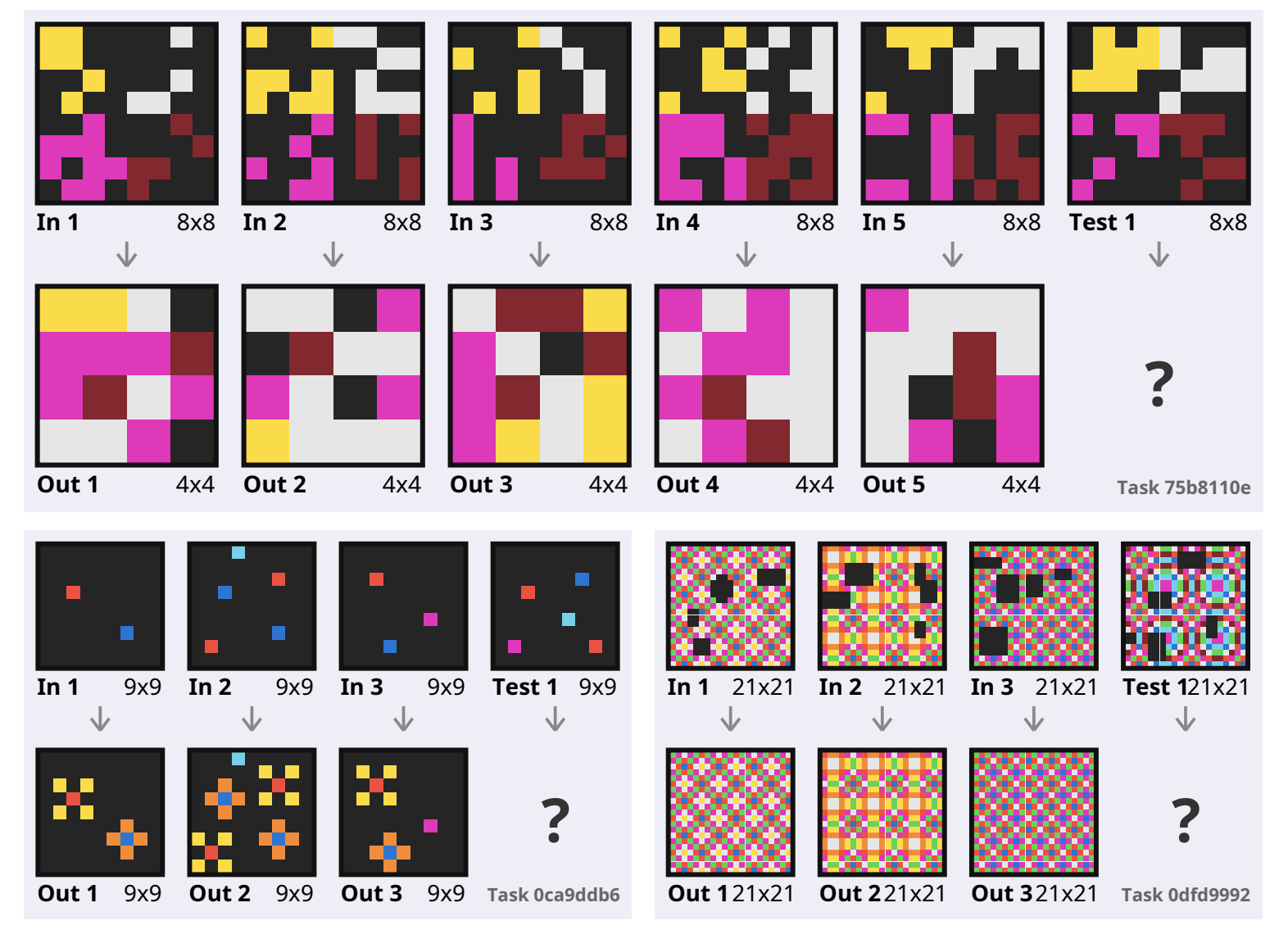
设是ARC任务的集合,是ARC中的一个任务,其中包含多个图片对,测试者需要根据给定的图片推理出图片对间的转化关系,一些ARC任务如下图:
DreamCoder的原理总结如下:DreamCoder分为三个阶段,第一个阶段称为“waking phase”,在该阶段DreamCoder会生成很多的程序,判断程序是否解决了某个任务(解决任务是指给定新的图片正确预测其对应的图片对),并保存能解决问题的程序。这是一个暴力搜索的过程,但是较短的程序会被优先考虑,基于奥卡姆剃刀原理。
DreamCoder的核心是“Abstraction Sleep”和“Dreaming Sleep”阶段。Abstraction Sleep阶段会对waking阶段生成的程序进行重构(refactoring)操作,如:假设使用翻转操作解决了某一个任务,就在翻转操作的基础上加入其他操作。在3步之内重构的程序会被暂时保留,如果有解决了其它任务的程序经过重构也得到了相同程序,换句话说,由两种waking阶段保留的不同的程序经过重构得到了相同的程序,那么就将这个相同的程序视为primitive,并在下一步waking阶段当做原子操作搜索新的程序。直观上来看,这个相同的程序可以视为不同任务间相同的概念。
在waking phase阶段的搜索空间是巨大的,为了进行启发式搜索,Dreaming Sleep阶段通过训练一个神经网络辅助搜索方向。该神经网络的输入是任务对,输出是一个程序。这个神经网络的功能很像蒙特卡洛树搜索中的评估函数,可以进行大量剪枝。
使用该方法在ARC任务上进行实验,在ARC简单任务上的正确率为16.5%,在ARC困难任务上的准确率为4.5%,虽然不及手工设计操作的算法,但是对于非手工设计的方法正确率高出很多。
LOGICSEG: Parsing Visual Semantics with Neural Logic Learning and Reasoning
语义分割是CV中的一类任务,其目标是把图像中的像素划分到某个类别中。之前的语义分割算法仅仅在像素层面上进行操作,并没有考虑不同层级类别之间的关系。这篇文章提出的LOGICSEG在训练和推理时加入了用一阶逻辑表示的知识用于提升语义分割的性能。
这篇文章中的知识是人工定义好的,主要是层级知识。如桌子和椅子是家具,瓶子和盘子是容器,而容器和家具是物品等。与其它语义分割算法不同,该文章将一个像素在不同层级进行了划分,如(物品->盘子->锅)。对层级之间该文章提出的约束如下:不同层级的概念应该相对应且相同层级的概念是不同的。如:如果一个像素被预测为床,那么它的上一层该被预测为家具,如果一个像素被预测成家具,那么它的下一层要么被预测成床,要么被预测成桌子,要么是其它预先被定义的属于家具的物品;如果一个像素被预测成床,那么它一定不能被预测成桌子。
由于加入的是符号逻辑,所以并不能直接用于神经网络优化。这篇文章提出的办法是将逻辑放松为模糊逻辑使之可微。并将约束写成损失函数再进行梯度下降优化。
这篇文章在推理阶段也用到了知识。具体做法是在预测某个像素的某个层级的类别时考虑其相邻层级的类别。如:在预测某个像素能否被划分为家具时,考虑其是否能被划分为桌子和物品。换句话说,如果一个像素同时被划分为物品和桌子,那么它属于家具的概率就很高。如果一个像素越有把握被分为某一个层级的概念中,那么它对相邻层级的划分的影响就越大。在具体实现中,对某一层级的预测概率会作为权重影响相邻层级的预测,而相邻层级的预测被影响后又会反过来影响当前层级的预测。这是一个迭代的过程。
αILP:thinking visual scenes as differentiable logic programs
这篇文章解决的问题是视觉ILP问题(visual ILP)。视觉ILP的问题与传统的ILP不同的点是其输入为图片,目的是学习一些规则来根据图片中物体的关系判断图片为正例还是负例。
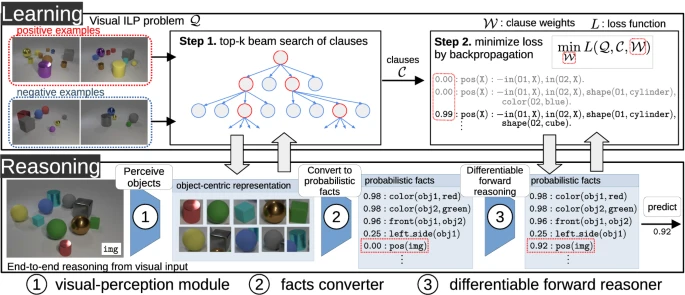
由于输入的是图片而不是符号,因此需要引入感知模型是非常容易想到的。简单来说,这篇文章的做法是,使用感知模型识别图片中的物体(可能有很多,都识别出来),然后将捕捉到的物体的特征或物体间的关系转化为概率事实,如物体颜色为红色的概率 ,两个物体位置相近的概率等。这一步需要人工设计neutral predicate来实现,具体过程参考原文。
将图片转化成符号后,可以开始进行ILP规则的学习。由于得到的事实是有概率的,所以学习规则的过程与传统的ILP不一样。文章的做法是先使用top-k beam搜索选择前k个最优的规则(如果某个规则能覆盖很多正例,那么它就是较优的),在此过程中使用了downward refinement operator来降低覆盖的正例数量以及mode declarations技术进行剪枝。
得到前k个最优的规则后,αILP需要对规则赋予权重,对于每条规则,αILP赋予的权重是一个维的向量,赋予权重是为了后续的differentiable reasoning。规则的权重是通过梯度下降学习出来的,在文章中使用的是交叉熵损失函数。
到此,我们得到了带有权重的事实和带有概率的规则,接下来就可以使用这些事实和规则进行reasoning来判断一张图片是否为正例。由于引入了概率,该步与传统的逻辑推理也不同,αILP使用了一种可微的方式来进行推理并得到图片为正例的概率。
以上是αILP的流程。整个reasoning过程都是端到端且可微的。这意味着当模型训练好后,输入图片就可判断该图片为正例的概率。